Es ist einige Zeit vergangen nach einer öffentlichen Auseinandersetzung ( hier und hier ), die meiner Meinung nach eine Menge Probleme auf unterschiedlichsten Ebenen aufzeigt, wenn es darum geht, mit Schülerinnen und Schüler in der Schule in einer gesicherten Umgebung digital zu arbeiten. In Deutschland firmiert eine solche Umgebung unter dem Schlagwort „Bildungscloud“.
Was ist für mich eigentlich wünschenswert, gerade unter dem Aspekt, dass in Schule sehr individuelle Lernprodukte von Schülerinnen und Schülern entstehen? Die sind natürlich unfertig ( das ist das Wesen eines Lernprozesses ). Sie erfordern je nach Entwicklungsstand von Schülerinnen und Schülern einen Schutzraum ( nicht jeder junge Mensch bewegt sich reflektiert und kompetent im Internet).
Und – das ist ja „nur“ die eine Seite der Medaille. Im Vordergrund für Lehrkräfte, Schülerinnen und Schüler sowie Eltern stehen natürlich auch die Funktionalität und die intuitive Bedienbarkeit – (Daten-)Schutzfragen stehen da oft im Hintergrund, weil Bequemlichkeit verlorengeht und dann toben die emotionalen Grabenkämpfe ( z.B. hier ).
Derweil gibt es Lehrkräfte, die dieses Problem individuell für sich bereits gelöst haben, z.B. Lisa Rosa oder Andreas Kalt. Auf viel niedrigerem Niveau habe ich das in meinem Unterricht auch schon oft gemacht. Nur brauchten wir alle dafür keine Lernplattform oder Schulcloud. Allerdings ist ein Mindestmaß an Kenntnissen im Bereich Datenschutz und im Umgang mit Webtools erforderlich (z.B. um dabei keine personenbezogenen Daten zu produzieren) – viele Lehrkräfte sind bereits bei vermeintlich kleinen Schritten im digitalen Raum restlos überfordert. Da macht eine gemeinschaftliche Lösung inkl. Wartung, technischem- und Anwendersupport einfach Sinn.
In einer idealen Welt
In einer idealen Welt haben wir
- eine Plattform auf OpenSource-Basis, die von allen Beteiligten im Hinblick auf Funktionalität und Bedienbarkeit akzeptiert ist
- einen gut aufgestellten technischen und Anwendersupport
- eine dezidierte Trennung von personen- und inhaltsbezogenen Daten
- die technische Bereitsstellung (Hosting) durch die öffentliche Hand
- dokumentierte Schnittstellen zu kommerziellen Anbietern (z.B. Unterrichtsmaterial, Medien, interaktive Übungen), die eine Anonymisierung der Schülerdaten ermöglichen
In der Realität
Die Punkte 1–2 gibt es zurzeit nur im kommerziellen Bereich – da muss man auf die Punkte 3–5 verzichten. Die Punkte 3–5 gibt es nur bei den größtenteils gescheiterten Länderplattformen. Da muss man zurzeit aber auf die Punkte 1–2 verzichten – zumindest zu 50–60% der jeweiligen individuellen Anforderungen.
Formal, d.h. rechtlich komplett abgesichert, ist keine der denkbaren Varianten – damit haben sämtliche Entwicklungsteams übrigens auch stark zu kämpfen – technisch wäre prinzipiell viel möglich, aber die Rechtsnormen geben das i.d.R. noch nicht oder nur mit großen verwaltungstechnischen Klimmzügen – z.B. die qualifizierte Einwilligung – her.
Das öffnet das Tor für Kritik. Kommerzielle Lösungen von Google, Microsoft oder Apple sind „böse“, weil sie Daten der Schülerinnen und Schüler verarbeiten. Öffentliche Lösungen sind entweder „böse“, weil sie – mit wenigen Ausnahmen – die Funktionalität nicht bieten, Rechtsnormen nicht erfüllen oder wahlweise intransparent entwickelt und finanziert werden (faktisch stimmt das alles sogar).
Was also tun?
Variante 1:
Man zwingt multinationale(!) Konzerne durch Rechtsnormen dazu, ein hohes, vom Staat definiertes Schutzniveau für die Verarbeitung von Schüler- und Verwaltungsdaten zu gewährleisten. Man schafft Rechtssicherheit z.B. durch eine staatliche Zertifizierung. Das ist nicht so trivial. Wir haben im Bereich der Politik und teilweise auch in der rechtlichen Unterstützung nach meiner Einschätzung nicht das notwendige Know-How dafür. Ich prophezeie, dass die dabei entstehenden Rechtsnormen nicht ihren eigentlichen Zweck erfüllen werden. Die Big5 waren die ersten, die z.B. komplett auf die DS-GVO eingestellt waren und nutzen diese, um noch mehr Zugriffsmöglichkeiten zu erhalten – können sie auch. Da gibt es ausreichend juristisches Know-How.
Variante 2:
Wir entwickeln öffentlich finanzierte Lösungen und schaffen einen rechtlichen Rahmen zu deren Nutzung. Das ist nicht so trivial. Wir haben im Bereich der Politik, im technischen Bereich und teilweise auch in der rechtlichen Unterstützung nach meiner Einschätzung nicht das notwendige Know-How dafür. Zudem ist der Staat als Arbeitgeber für die dazu notwendigen idealistischen Menschen z.B. durch Bürokratievorgaben aber auch Gehaltsbindung durch Tarifrecht nicht konkurrenzfähig. Deswegen wird ja versucht, solche Entwicklungen outzusourcen – z.B. ans HPI. Das ist aber in der Wahrnehmung in der Öffentlichkeit oft auch „böse“. Was muss also ein kommerzieller Anbieter auf diesem Feld für Kriterien erfüllen, um nicht „böse“ zu sein?
(Ich bin kein Freund des Ansatzes des HPI. Nicht umsonst ist Bayern mit Mebis eigentlich schon an weitesten, weil dort etwas Bestehendes genutzt und erweitert wird).
Einschätzung
Ich glaube, dass jeder, der undifferenziert(!) auf öffentliche oder „unbequeme“ OpenSource-Ansätze „schießt“, im Grunde die Variante 1 fördert. Darauf wird es hinauslaufen. Die meisten Lehrkräfte, die digital unterwegs sind, wird es freuen. Ob es ein Gewinn für die Demokratie wird … – wir werden sehen. Eine Trennung von personenbezogenen und inhaltsbezogenen Daten (das würde technologisch eine effektive Kontrolle schaffen) ist dort erfahrungsgemäß weder gewünscht noch vorgesehen – das ist schlicht nicht das Geschäftskonzept.
Komplett die Hoffnung habe ich verloren, dass sich derartige Fragestellungen über journalistische Medien in den öffentlichen Diskurs einbringen lassen. „Digital“ ist in der Berichtserstattung in der Regel gleich „Tablet“ oder „interaktive Tafel“ – Gerätefokussierung von 2003–2019.
Ich bilde mir noch ein, dass das prinzipiell möglich wäre und halte auf meinen Fortbildungen tapfer dagegen (da kommen noch drei weitere Teile).

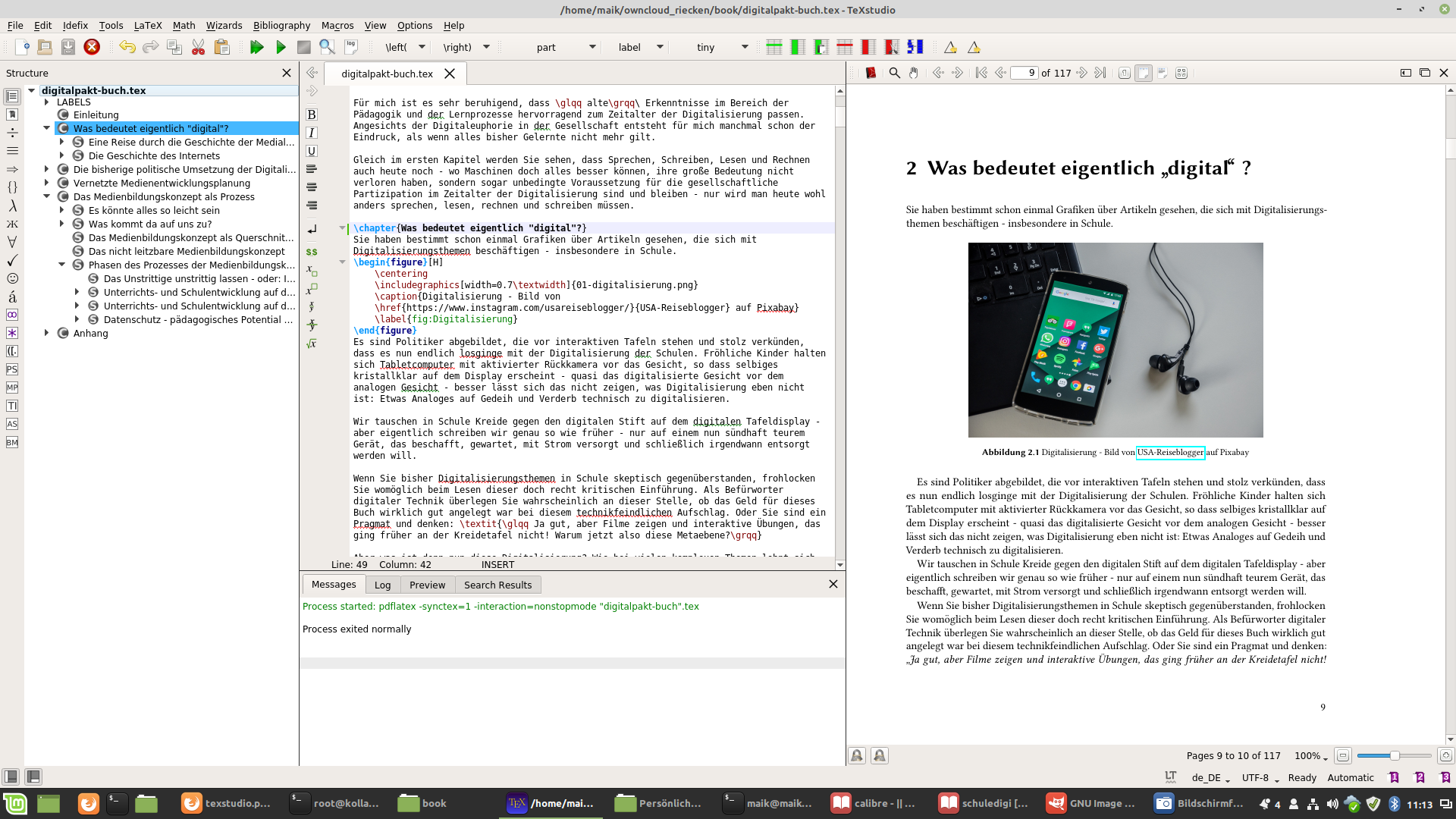
![\[ U_{H(Ox/Red)} = U_{H(Ox/Red)}^0 + \frac{ 8,314472 \frac{J}{mol \cdot K} \cdot 297K}{z \cdot 96485,3399 \frac{C}{mol}}\cdot 2,3 \cdot lg \left( \frac{c(Ox)}{c(Red)} \right) \]](https://www.riecken.de/wp-content/ql-cache/quicklatex.com-b0f440cc950369e4f2891263f18f8577_l3.png "Rendered by QuickLaTeX.com")